Collective Communication Optimization in Beowulf Clusters
Click here to download MPIM source.
Summary
This project aims to improve the performance of workstation clusters for
a broad variety of projects where Broadcast-style communications are
important. This research is funded by NASA's
Applied Information
Systems Research program.
Sample Results
Communications Speedups
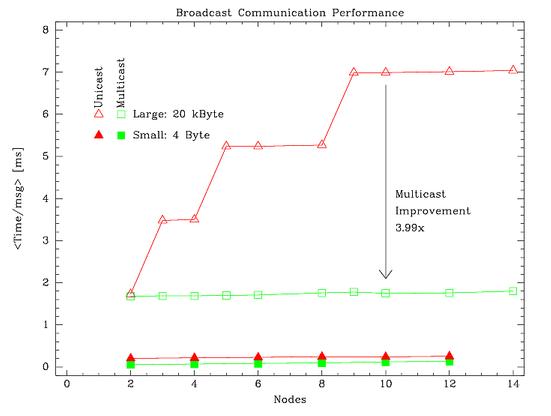 This figure shows the log2(nodes) speedups are a reality for
large messages. Both conventional MPI broadcast (triangles) and new
Multicast-based broadcasts (squares)
are essentially at the limit for Fast Ethernet
(1.6ms for 20kB) when only one communication is required. But the
series of unicasts in the conventional broadcast quickly falls behind
while the multicasts require a nearly constant amount of time.
Essentially perfect scaling.
This figure shows the log2(nodes) speedups are a reality for
large messages. Both conventional MPI broadcast (triangles) and new
Multicast-based broadcasts (squares)
are essentially at the limit for Fast Ethernet
(1.6ms for 20kB) when only one communication is required. But the
series of unicasts in the conventional broadcast quickly falls behind
while the multicasts require a nearly constant amount of time.
Essentially perfect scaling.
In contrast, the improvements for small messages are simply due to the lack
of round-trip in our NACK-based reliable multicast scheme, and other
minor UDP over TCP efficiencies. These cut the communication time by less
than a factor of two throughout these cluster sizes.
Science Speedups
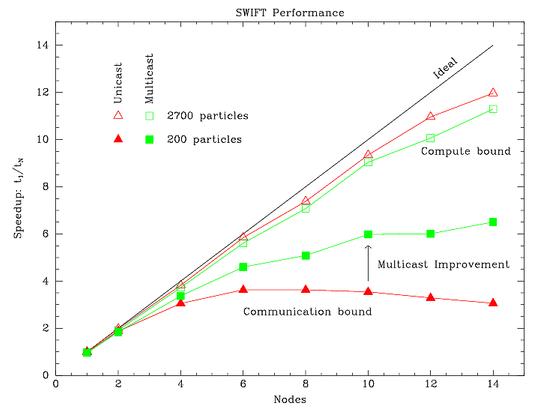 Preliminary results in an Nbody dynamical integrator.
When there are many bodies (upper curves),
the application is mostly compute bound,
so either communication scheme allows good scaling. But
towards the extreme when
there are few particles per node (14p/n in the most extreme example here),
communications dominate. Indeed, with traditional broadcasts, the
application is slower with more than ~6 nodes.
Our new multicasts improve the performance of this application by a
factor of two in this communication dominated regime.
Preliminary results in an Nbody dynamical integrator.
When there are many bodies (upper curves),
the application is mostly compute bound,
so either communication scheme allows good scaling. But
towards the extreme when
there are few particles per node (14p/n in the most extreme example here),
communications dominate. Indeed, with traditional broadcasts, the
application is slower with more than ~6 nodes.
Our new multicasts improve the performance of this application by a
factor of two in this communication dominated regime.
Recent News
Project Abstract
We propose to develop a transparent drop-in software module to
accelerate significantly many classes of scientific simulations
conducted on popular ``Beowulf'' parallel computing clusters. This
module will replace the point-to-point broadcast model in the commonly
adopted software layer (MPI) with reliability-enhanced socket
multicasts. This module will significantly increase the speed of the
collective communications which frequently dominate the execution time
of Nbody2
calculations, such as our gravitational simulations
of solar system formation and evolution. Because the expected
improvement in these communications is of order
log2Nnodes
(a factor of 7 for large clusters), even tree-based calculations used
in a broad array of planetary and astrophysical applications will
benefit. In addition to the development of the software package, we
will demonstrate the performance improvement with characteristic
calculations and provide a software module to make this enhancement
easily available to the rapidly growing community of scientific (and
industrial) users of similar clusters.
Development Cluster
We have a small Beowulf cluster of Intel-based computers for development
work, unimaginatively called AIS.
Each of 4 nodes (+1 backup for parts) has:
- Gigabyte GA-6VX7-4X motherboard based on the VIA Apollo Pro 133A chip.
We actually wanted Asus P3V4X motherboards, but couldn't easily get
the Slot-1 format CPUs. See note (6/29/00 News) about BIOS before
following this selection!
- Intel PIII Coppermine CPUs running at 733 MHz w/ 133 MHz FSB
- 128MB PC133 SDRAM, except master which has 256MB
- Seagate ST310212 disk, except master & backup which have
Seagate ST328040A disks
- NetGear FA310TX 100 Mbit PCI ethernet card
- RedHat 6.2 w/ custom-configured Linux kernel
The master node also has a monitor, CDROM, floppy,
keyboard, and a second ethernet
card. The nodes are connected by a fast-ethernet switch, currently a
NetGear FS105. Planned purchases include a variety of alternative ethernet
cards and switches, and eventually Gigabit network hardware.
You might also be interested in seeing the page about our production
cluster, Hercules.
Team
Peter Tamblyn / ptamblyn@astro101.com
Last modified: January 15, 2003